前言
大模型有三个先天局限:知识有截止日期、无法访问私有数据、信息不足时可能幻觉。
RAG 的思路很简单:先从外部知识库检索相关资料,再让模型基于这些资料回答。 本质上就是给模型配了一个「外挂知识库」。
本文按 RAG 的完整流程展开——切块、向量化、存储、检索、生成。
1. 总览:两阶段流水线
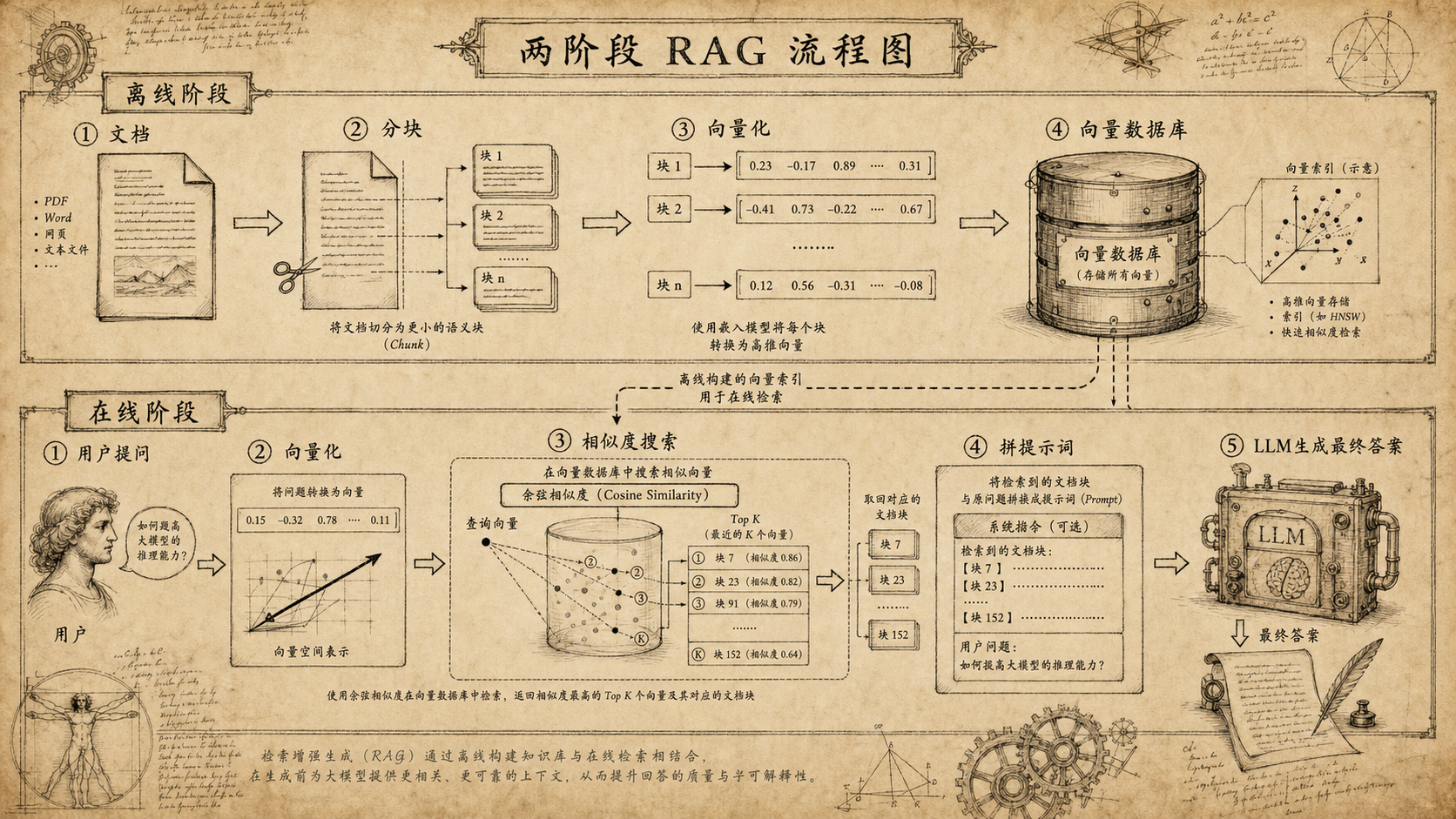
RAG 可以拆成一条清晰的流水线,分两阶段:
离线阶段。提前把知识库里的文档全部处理一遍,与用户无关:
文档 → 分块 → 向量化 → 存入向量库
- 分块:长文档切短,既保证每块信息密度够高,又不超出 Embedding 模型的输入上限
- 向量化:把每块文字转换成一串数字(向量),语义相近的文字向量坐标也相近
- 存入向量库:把向量存起来,后续按相似度查找
在线阶段。用户提问时才触发,链条很短:
提问 → 向量化 → 相似度搜索 → 拼进提示词 → LLM 生成
- 向量化:用同一个模型把问题也转成向量
- 相似度搜索:在库里找和问题向量距离最近的 K 个文档块
- 拼进提示词:把搜到的文档块和原问题组装成一条完整的提示词
- LLM 生成:模型基于检索到的资料回答问题
两阶段设计的关键在于,重活(向量化全部文档)在离线做完了,在线只需向量化一个问题、做一次近邻搜索,延迟很低。
本质上,RAG 把检索问题变成了数学问题。你不再需要理解文档内容来搜索——只需算向量之间的余弦相似度,在向量空间里找距离最近的几个点。
2. 分块:化整为零才搜得准
分块的核心矛盾很简单:块太大则信息稀释,块太小则上下文割裂。下面四种策略,从简单到复杂,覆盖了绝大多数场景。
2.1 固定大小分块
按字符数或 token 数等距切,最简单的方案,三行代码搞定。可以在相邻块之间加 overlap(滑动窗口),防止关键句被边界切断。
固定: [=======|=======|=======|=======]
带重叠: [=======|===]→[===|=======|===]→
优点是实现零成本、chunk 大小均匀方便批处理。缺点也很明显:可能从句子中间切断,无视表格、列表等文档结构。适合日志、纯数据等结构均匀的文本,或作为快速验证的基线。
2.2 递归字符分割
这是工业界公认的最佳起点,80% 的通用 RAG 场景用它就够了。原理是用优先级递减的分隔符逐层尝试切割:
段落("\n\n") → 换行("\n") → 句号("。") → 词边界(" ") → 字符("")
先尽量在段落边界切,不行退到句子,再不行退到词——始终落在最自然的断点上。
2.3 句子级分割
先用 NLP 工具(spaCy、NLTK)识别句子边界,再把连续句子打包成 chunk,保证绝不切碎单个句子。配合 ColBERT 等模型效果突出,但局限在于:多跳推理类查询(如「X 如何影响 Z」)单句几乎不可能包含足够信息,检索会落空。
3. 向量化:把文字变成数学
3.1 Embedding 是什么
Embedding 就是把文字转成一串数字(比如 1536 个浮点数),这串数字代表高维空间中的一个坐标。
"狗" → [0.8, 0.3, 0.1]
"小狗" → [0.75, 0.32, 0.12] ← 坐标相近
"猫" → [0.7, 0.28, 0.15] ← 也较近(都是宠物)
"汽车" → [-0.2, 0.5, -0.4] ← 很远
核心性质就一条:语义相近的文字,在向量空间中靠得近。
3.2 语义搜索原理
传统搜索靠字面匹配:WHERE content LIKE '%天气%' ——「今天天气不错」能命中,「晴朗的午后」就搜不到。
向量搜索不关心字面,只关心语义。Embedding 模型训练时见过大量文本,学会了「天气」和「晴朗的午后」在语境上相近,因此它们的向量坐标也贴近。数学上,计算两个向量的余弦相似度即可——夹角越小,语义越近。
3.3 值得注意的点
入库和查询必须用同一个 Embedding 模型。
不同模型产出的向量在不同的空间中,坐标无法互相比较——就像用北京坐标系的地图去匹配上海的坐标系。换模型意味着必须重建整个向量库。
4. 存储与召回:存向量,找最近
4.1 核心
不管用什么工具,存储和召回的本质只有三步:
存向量 → 算相似度 → 返回最近的 K 个
数据量小(几千条以内),存 JSON 遍历都行。上了百万级才需要向量数据库的专用索引(HNSW 等)。
4.2 召回
纯向量搜索靠余弦相似度,语义匹配强,但专有名词、编号等精确字段可能漏掉。
混合检索把向量搜索和关键词搜索(BM25)的结果融合,语义和字面互补。专有名词靠关键词兜底,同义词靠向量兜底。
**重排序(Rerank)**是「用慢换准」:先粗召 20 条,再用更精的模型重新打分,取 top 5。多一次模型调用,但相关性明显提升。
4.3 元数据
召回时只返回文本片段是不够的——你得知道它出自哪个文档、第几页、什么时候的版本。否则答案看似合理,溯源无从谈起。
参考
- Masturbyte — Building Production RAG Pipelines: The Complete Guide:2026 年全栈代码指南,混合检索、RRF、重排序、RAGAS 评估一应俱全,每个概念配可运行代码。
- Prem AI — RAG Chunking Strategies: The 2026 Benchmark Guide:整合四大基准的分块策略决策手册,7 种策略对比、调参建议、按文档类型的速查表。