前言
过去两年,AI Agent 经历了从概念到落地的快速演进。编码 Agent 率先成熟——Claude Code、Codex、OpenCode 等工具已经成为很多开发者的日常。
这些系统的底层架构有很多共通之处:LLM 调用、工具执行、上下文管理、会话持久化、扩展机制……但如果你想深入理解一个 Agent 是怎么跑起来的,去读 Claude Code 或 OpenCode 的源码并不现实——前者闭源,后者规模庞大且耦合度高。
pi 是一套开源的 Agent 开发包,涵盖 LLM 抽象、Agent 引擎、终端 UI 等核心能力,其中的编码助手只是它的一种产品形态。它适合作为学习 Agent 架构的入口,原因很简单:pi 的设计哲学是最小核心 + 扩展优先。Agent Loop、Context、工具、会话树和扩展系统这些基础层都放在明处,子代理、Plan Mode、权限确认这类更具体的“做事方式”则不硬塞进核心,而是留给扩展去实现。
这篇博客会逐层深入 pi 的架构,不只看"能做什么",更关注"为什么这样设计"。
1. Agent Loop:LLM 与工具的循环
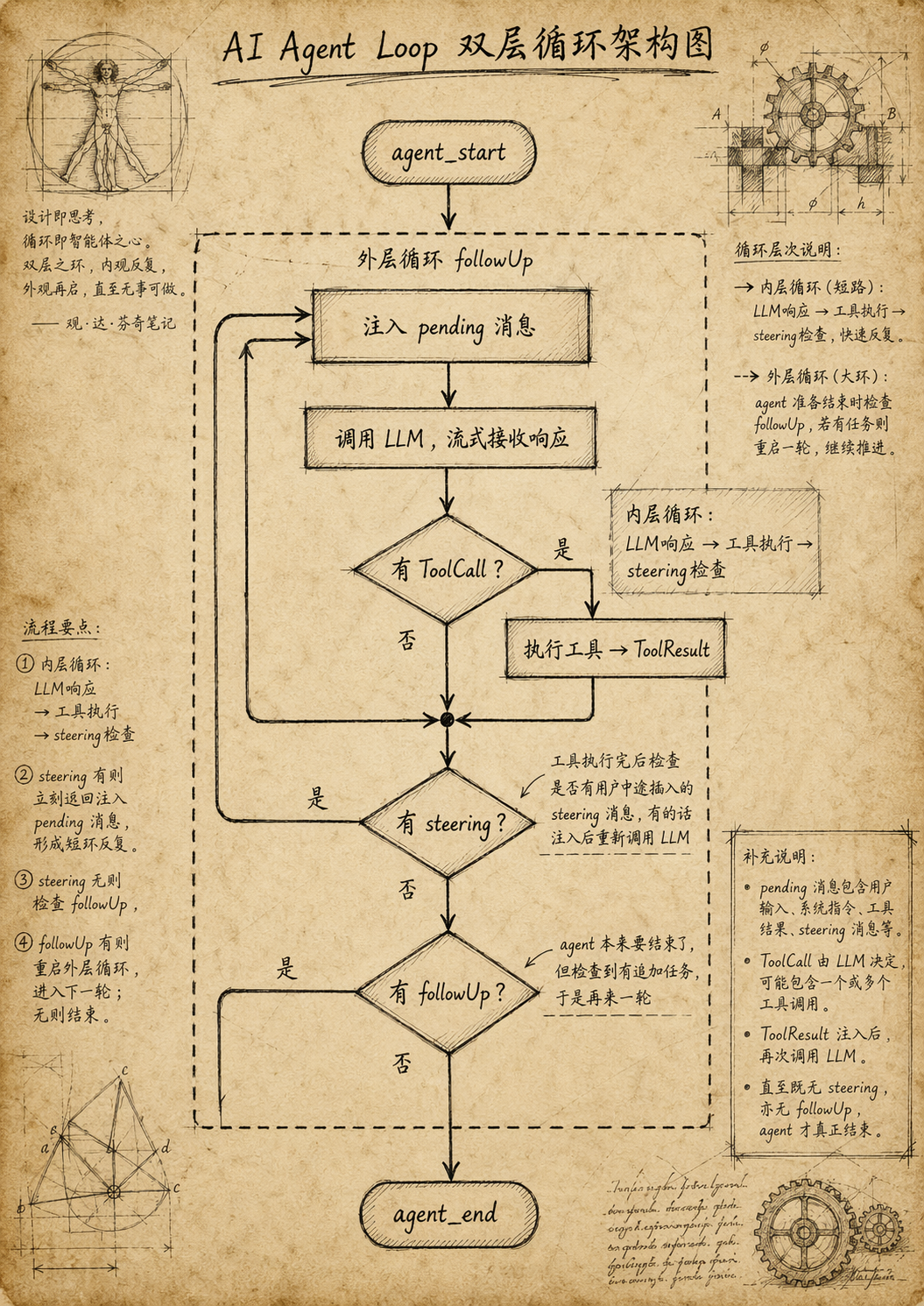
1.1 Tool Call 循环
当 LLM 的回复中包含 ToolCall 时,循环不会停止。pi 会:
- 从 LLM 回复中提取所有 ToolCall
- 执行工具,拿到 ToolResult
- 把 ToolResult 加入上下文
- 再次调用 LLM,让它看到工具结果并决定下一步
这个循环会一直转,直到 LLM 的回复中不再包含 ToolCall 为止。这就是 Agent 的核心——LLM 不只是生成文本,它通过工具与外部世界交互,根据结果自主决定下一步操作。
举一个具体例子:你对 pi 说"把 config.json 里的 port 改成 8080"。
Turn 1: LLM → ToolCall(read, {path: "config.json"})
→ ToolResult: 文件内容
Turn 2: LLM → ToolCall(edit, {path: "config.json", oldText: "port: 3000", newText: "port: 8080"})
→ ToolResult: 编辑成功
Turn 3: LLM → "已将 port 从 3000 改为 8080" (纯文本,无 ToolCall)
→ 循环结束
三个 Turn,两次工具调用,LLM 自主完成了读取→修改→确认的全流程。
当一次回复中包含多个 ToolCall 时,pi 默认并行执行;对写文件这类有冲突风险的工具,也可以配置为串行。
1.2 Steering 和 FollowUp:两种干预方式
Agent 在执行过程中,用户不是只能干等。pi 提供了两种消息注入机制,对应一个两层循环结构。
Steering(实时干预):当 agent 正在执行工具时,用户发送的消息会进入 steering 队列。当前 Turn 的工具全部执行完后,steering 消息被注入上下文,LLM 在下一个 Turn 就能看到用户的指示。比如 agent 正在批量修改文件,你发现方向错了,发一条"停,只改 config.json",agent 在当前这批工具跑完后就会收到你的指示。
FollowUp(后续追加):当 agent 完成所有工作、即将停止时,pi 会检查 followUp 队列。如果有消息,agent 不会退出,而是开启新的一轮循环处理这些消息。这适合"顺便帮我做个XXX"的场景。
结合起来看,内层循环处理 tool call 和 steering,外层循环处理 followUp。agent 只有在两层队列都为空时才会真正停止。
2. Context:LLM 看到的完整世界
Agent Loop 每次调用 LLM 时,传递的是一个 Context 对象。LLM 能做什么、知道什么,完全取决于这个对象里装了什么。理解 Context 的组装过程,就理解了 pi 如何向 LLM 描述世界。
Context 由三部分组成:System Prompt、Messages、Tools。
2.1 System Prompt
System Prompt 是 LLM 的“角色卡”,告诉它你是谁、能做什么、该怎么做。pi 会把角色定义、行为准则、当前启用的工具、项目上下文文件、Skills 列表、当前日期和工作目录拼接进去。
这里有两个关键设计:第一,LLM 只看到当前启用的能力,不会看到不存在或已关闭的工具;第二,Skills 采用渐进式披露,System Prompt 只列出名称、描述和路径,完整内容由 LLM 需要时再读取。这样既控制上下文长度,又保留了扩展能力。
2.2 Messages
Messages 就是 Agent Loop 中积累的对话历史:用户的输入、LLM 的回复、工具调用的结果。经过 convertToLlm() 过滤后,只保留 LLM 能理解的 user、assistant、toolResult 三种类型。
2.3 Tools
Tools 是工具的 JSON Schema 定义,告诉 LLM 每个工具接受什么参数、参数的类型和含义。这不是 System Prompt 里的文本描述,而是结构化的 schema,LLM 据此生成合规的 ToolCall。
3. 工具设计:LLM 的手和眼
工具不是简单的“函数调用列表”,而是 LLM 观察世界和改变世界的接口。pi 的内置工具可以分成三类:read/grep/find/ls 负责观察项目,edit/write 负责改变文件,bash 负责调用外部环境。
这三类能力的风险不同:读操作主要提供信息,写操作会改变项目状态,bash 的边界最大。因此,工具层不能只关心“能不能调用”,还要处理输出截断、并发冲突、错误反馈和权限控制。
3.1 截断策略
工具输出最终会进入上下文,但 LLM 的窗口有限。pi 用行数和字节数做双重限制,哪个先到就截哪个。典型的两个方向是:
- read 用
truncateHead——保留文件开头,截掉尾部。截断后会在输出末尾追加提示,比如[Showing lines 1-2000 of 50000. Use offset=2001 to continue.],告诉 LLM 可以用offset参数继续往下读。 - bash 用
truncateTail——保留命令输出的末尾,截掉开头。因为命令执行的关键信息通常在最后:错误信息、退出码、最终结果。
这让 LLM 具备了“翻页”能力:先看关键部分,必要时再继续读取。
4. Compaction:上下文的瘦身术
Agent 的对话历史会不断增长,但 LLM 的上下文窗口有限。pi 的解决方案是 Compaction(压缩):用一段摘要替代旧消息,释放上下文空间。
4.1 触发时机
压缩会在接近上下文窗口上限时自动触发;如果已经触发 context overflow,pi 也会先压缩再重试。用户也可以手动触发,并用自定义指令控制摘要侧重点。
4.2 压缩流程
压缩真正难的地方不是“总结聊天记录”,而是安全地切分历史。一次 Agent 操作往往由用户请求、assistant 的工具调用、toolResult、下一次 assistant 决策组成。如果从中间切开,LLM 可能只看到工具结果,却看不到对应调用。
所以 pi 会从最新消息往回保留一段近期上下文,并寻找安全切割点。切割点不会落在 toolResult 中间,因为工具结果必须和对应的工具调用保持连续。被切掉的旧消息会序列化成文本,再由 LLM 总结为目标、进度、关键决策、下一步和文件操作记录。
加载上下文时,旧消息不再全部进入 LLM,而是由摘要加上最近保留的消息共同组成新的上下文。
压缩是有损的——细节会丢失。但完整的对话历史仍然保存在会话文件中。
5. 会话树:无损回溯与分支探索
编码场景下,LLM 试错是常态。会话树解决的不是存储问题,而是探索问题:Agent 的执行路径可能出错,但错误路径本身也有信息价值。
线性对话模型下,你要么截断后面的历史,要么新建一个无关联会话。pi 则用树结构管理会话:除 header 外,每条 entry 都有一个 parentId 指针,文件仍然是 append-only 的 JSONL,只是通过指针决定当前走哪条分支。
5.1 parentId 链式结构
新的 entry 会追加到文件末尾,挂在当前 leaf 下面。branch() 只移动 leaf 指针到更早的 entry,不复制、不删除数据;下一次 append 自然形成新分支。
5.2 从 leaf 到 root 的路径遍历
Agent Loop 仍然需要线性消息列表。buildSessionContext() 会从当前 leaf 回溯到 root,只收集当前路径上的 entry;树上其他分支不会进入 LLM 上下文。
5.3 分支切换时的摘要
切换分支时,pi 可以对“被放弃的那条路径”生成摘要,并挂在新分支起点。这样新分支不会继承旧分支的完整上下文,但仍能知道之前探索过什么。
5.4 与压缩的关系
树结构解决“回到之前某个节点重新开始”,压缩解决“上下文太长需要瘦身”。两者都只追加 entry、不修改已有数据。
6. 插件化:最小核心,无限扩展
pi 的扩展系统是它区别于其他 Agent 框架的核心设计。前面提到的 Agent Loop、工具、Context 都可以在扩展中注册和拦截。
6.1 整体架构
扩展本质上是一段启动时加载的 TypeScript 模块。pi 会先扫描并加载扩展,再执行扩展的工厂函数完成注册;Agent 运行时,ExtensionRunner 在关键节点按顺序调用对应 handler。前一个 handler 的输出会成为后一个的输入,部分事件可以短路(block / cancel)。
抛开终端 UI 这类偏产品层的能力不谈,pi 的扩展能力主要可以分成三类:注册、拦截、注入。
6.2 注册——给系统加东西
注册的本质是给 Agent 增加新的可见对象:工具进入 LLM 的 tool schema,命令进入用户交互层,Provider 进入模型选择层。模型不关心工具来自核心还是扩展,只会根据当前上下文里的描述和 schema 决定是否调用它。这也是 pi 能保持小核心的原因:核心只定义扩展点,具体能力在外部生长。
6.3 拦截——在关键节点介入
拦截让扩展可以在 Agent 生命周期的关键节点介入:工具执行前的 tool_call、工具执行后的 tool_result、LLM 调用前的 context、Provider 请求前的 before_provider_request、压缩前的 session_before_compact、分支/会话操作前的 session_before_tree 等。
这些事件是链式传递的。多个扩展监听同一事件时,前一个扩展的修改会叠加到后一个扩展看到的输入上。
一个典型的拦截场景是权限控制。权限确认并不需要写进 Agent Loop 本身,而是可以作为 tool_call 之前的一道门:
LLM 生成 bash ToolCall
→ permission-gate 扩展检查命令
→ 安全则放行
→ 危险则请求用户确认
→ 用户拒绝时返回 block,工具不执行
这样 Agent Loop 不需要内置固定权限策略,不同团队可以用扩展定义自己的安全边界。
6.4 注入——主动操作 Agent 状态
注册和拦截主要是在 Agent 经过某个节点时被动生效,注入则让扩展主动改变 Agent 状态:塞入新消息、写入自定义会话 entry、切换模型、调整思考深度、动态启停工具。
这让扩展不只是“插件按钮”,而是可以参与运行过程。比如 git checkpoint、文件监听、自动消息注入都不是核心功能,但都可以通过同一套生命周期和状态注入机制实现。